October 30, 2019
A Universal Async Abstraction for C++
Executors - of which P0443R11 is one of the latest iterations - is poised to be the most fundamental library addition to C++23.
But what is it about?
It is first and foremost a quest to find the most basic building blocks on top of which one could build asynchronous, concurrent and parallel code, whether it be on a small chip or a supercomputer with thousands of CPUs and GPUs.
This is not an easy task and has kept many experts and many companies busy for many years.
This is important work as it would allow, among other things:
- Parallel algorithms
- Networking
- Async I/O
- Audio
- Windowing systems
- Coroutines
- Async Ranges
- Heterogeneous computing
- …
To compose nicely and share many algorithms.
At least, that’s the goal.
If iterators are the basis of operations of algorithms (of which ranges and views are abstractions), what is the basis of operations of async programming?
At this point, I should point out that despite doing my best not to mischaracterize anyone, and to be as technically accurate as I can, executors have a very long history in the committee and I only took an interest in this whole thing recently - I am a bull in a china shop, not a domain expert.
That being said, I will not exactly focus on P0443R11, but on something I find a bit more refined, not yet in a paper.
The result of that work will mostly be a few concepts, some customization points and a few algorithms to compose all of that.
First thing first.
Execution Context
An execution context represents the context in which you want to execute a piece of code (see? simple). That can, for example, be a thread pool, an event loop, Grand Central Dispatch, a GPU, a vectorization unit (although it’s still unclear to me how that fits into the picture) or even the current thread - in which case we talk of inline execution context.
[Note: Because there are inline execution contexts, executing some work on an execution context does not systematically imply asynchrony.]
Receiver
A receiver represents the code we want to run on an execution context. In simplest terms, a function. But, an important point of the design of the executors proposal is to systematically provide error handling and error management so there are 3 functions we need to provide.
template <typename R, typename Error, typename... Value>
concept receiver = requires(R &r Error... e, Value&&...v) {
set_value(r, v...); // happy path
set_error(r, e); // error
set_done(r); // cancelation
};
This is bad blog code - In reality receiver will be split in receiver and receiver_of to allow overloading set_value.
The standard will probably provide a receiver that wraps an invocable, throws on error and does nothing on cancellation.
So maybe we could write something like this:
fugazzi_async(execution_context, as_receiver([] {
fmt::print("Hello from an executor");
}));
But now we have a problem.
By the time fugazzi_async has returned, the lambda may have been enqueued, somewhere.
Or even already executed.
The traditional way to solve that is to use a future and a promise, sharing a ref counted shared state, heap allocated.
But that is, to put it mildly, not optimal.
Sender and Scheduler
So what we can do instead is to ask the execution context to reserve a slot. Eric Niebler calls that a lazy future, the name chosen for the concept is sender.
sender because it sends its result to a receiver.
Great, But how do we get a sender?
We could, just do thread_pool.give_me_a_sender(),
but for the sake of genericity and because we probably don’t want to expose our thread pool to everyone,
we add a level of indirection (that always works).
Also, I suppose that in some cases the execution context may never be materialized in the type system.
scheduler represents a lightweight handle to an execution context. Its only purpose is to create senders.
execution context -> scheduler -> sender.
thread_pool tp(std::thread::hardware_concurrency());
auto scheduler = tp.scheduler();
auto sender = scheduler.schedule();
There are other ways to create senders, for example
auto async_read(device, buffer) -> sender can be a function that creates a sender able to enqueue a read operation on a reactor queue.
Timers would also be senders, etc
Once we have a sender, we can start thinking about doing some work. If you have been paying attention, so far we have done very little work.
With good reason. By preparing our operations lazily we can compose them with algorithms. Let’s not get ahead of ourselves.
For now, we just need a function that takes a sender and a receiver and
submits the sender for execution.
submit(my_sender, my_receiver);
If the execution context of my_sender is, for example, a thread pool
the receiver will be enqueued and then executed on a thread of that thread pool (by calling my_receiver.set_value()).
And some work will finally be done. And that’s it? According to P0443R11, yes, pretty much.
But there is a catch.
Let’s write a thread pool to illustrate
class my_first_thread_pool {
std::vector<std::any_receiver<void>> work;
void enqueue(receiver auto r) {
std::any_receiver<void> oh_no{std::move(r)}; // 😰
work.emplace_back(oh_no); // 😱
/* ... */
}
/* ... */
};
To implement our thread pool, enqueue function (which is called by submit(sender, receiver), we do have to pay the cost of type-erasure (which probably implies an allocation),and another allocation (at least) to put our type-erased receiver on the heap so we can have a container of them).
While this is fine for many people, it is not ideal and a deal-breaker for some.
Is there a better way? Yes. But at this point we diverge from P0443R11. Note that I invented nothing of what follows - there will be a paper about these ideas in the future.
Everything can be improved by one more level of indirection, so let’s do that.
Operation
Instead of a submit(sender, receiver) that submits the work immediately, we can have a function that takes a sender, a receiver, and returns an aggregate of both, but do nothing else. Let’s call that function connect :
thread_pool tp(std::thread::hardware_concurrency());
auto scheduler = tp.scheduler();
auto sender = scheduler.schedule();
auto op = connect(std::move(sender), as_receiver([] {
return 42;
}));
The return object op satisfies the operation.
Again, this does nothing but preparing some workload that can be enqueued in the execution context later.
But the nice thing about that extra indirection is that, if we need to enqueue a single object and wait for it, you can allocate it on the stack. And while you would still need to type erase the receiver, now you only need a virtual call to do it.
It might be better to explain with some code:
struct schedule_operation_base {
virtual void set_value() = 0;
};
template <sender S, receiver R>
struct schedule_operation : schedule_operation_base {
//...
void set_value() override {
my_receiver.set_value();
}
private:
R my_receiver;
};
Each sender type has its own specific operation type.
template <receiver MyReceiverType>
auto(thread_pool::sender, MyReceiverType my_receiver)
-> thread_pool::schedule_operation<thread_pool::sender, MyReceiverType>;
This in turns allows us to store the execution context’s associated state in each operation rather than in the execution context itself. So instead of having a container of work in the thread pool, we can make an intrusive linked list of all the queued operations.
[Note: This implies that operation can neither be copied nor moved]
Because this might be hard to visualize, here are some visualization of how a regular thread pool keeps track of its state (enqueued work):

And what the operation machinery allows us to do:
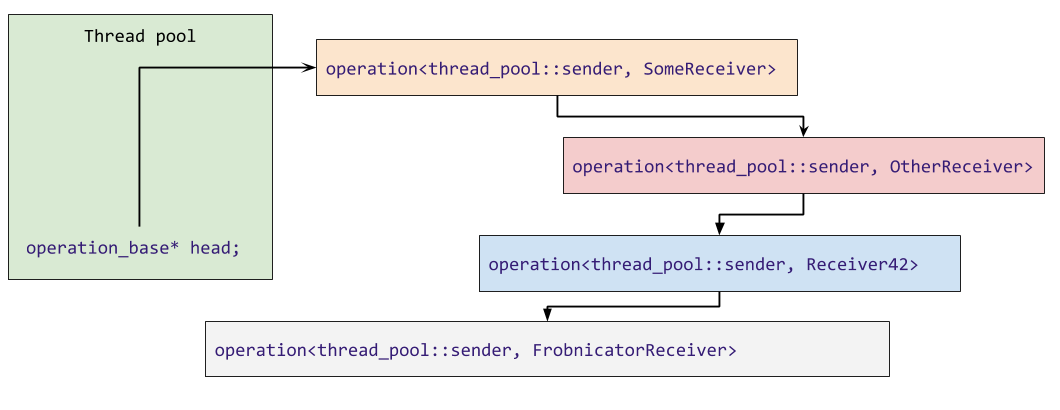
In the ideal case, there is no heap allocation and enqueuing/dequeuing work is setting a couple of pointers which means that the mutex that protects the work queue of our thread pool is held for a very short time.
Of course, sometimes you will need to enqueue many operations at once or not want to wait for your operation to complete.
In these cases, you will need an extra function to heap
allocate (or allocate with a custom allocator).
The heap allocating function is called spawn.
void spawn(sender, receiver);
spawn wraps the receiver in another receiver that will
destroyed the operation whenever one method of the receiver is called.
This makes the ownership model rather simple. A feat for asynchronous code.
spawn is also the only point in that whole system
that has to deal with allocators (allocators themselves
probably need to be transferred to senders for composed operations).
To recap things a bit, here is a diagram of the entire thing:
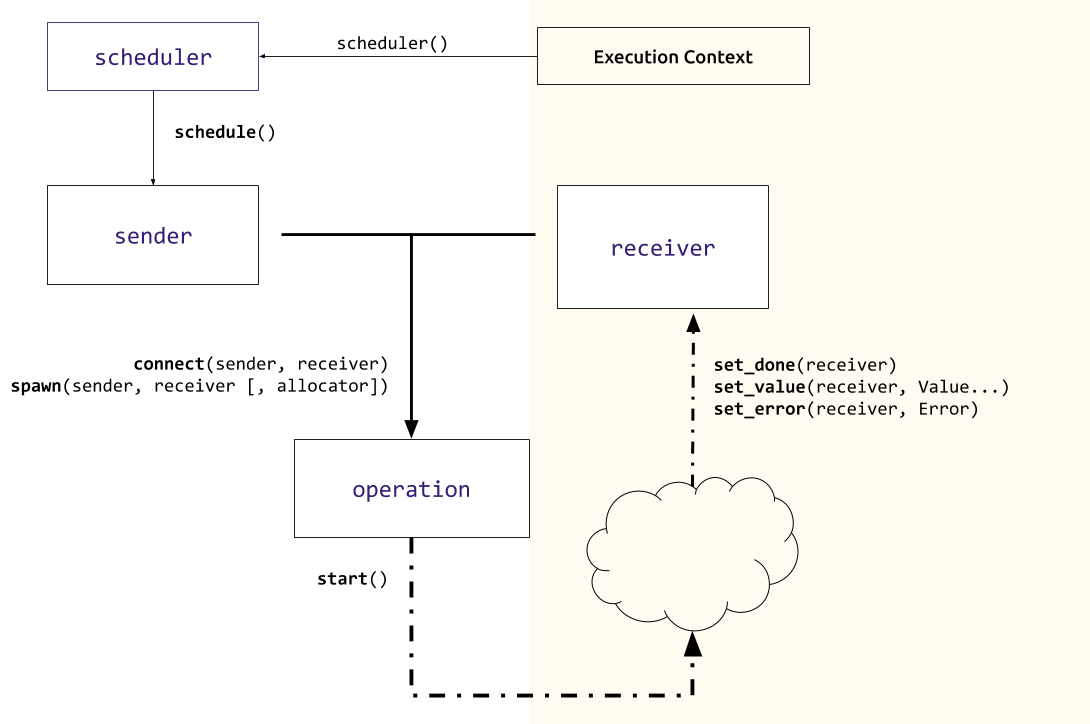
Everything is a sender
Thread pools usually have a wait method.
But with the sender/receiver model, the thread pool can instead provide a method returning a sender and we can attach that sender to a receiver that will be invoked when the thread pool is empty, by the means of a generic wait algorithm.
thread_pool p;
//...
wait(p.depleted());
Many such algorithms can be provided, including:
when_allwhen_anythen/sequence- An asynchronous version of
transform
These algorithms could be used to, for example, write a better future. But I haven’t played with all of that yet.
A coroutine to rule them all.
One aspect that I find critical when yet-to-come asynchronous facilities are provided in the standard, is that they have first-class coroutines support. coroutines should be how 99% of people write asynchronous code. It’s what they are made for and reduce significantly the change of blowing one’s feet off.
But at the same time for a few use cases, coroutines will not be suitable.
So we need a way to be able to use coroutines that is trivial and not have to pay for it when we don’t want to use them.
Seems complicated?
We actually need to define a single function:
template <sender S>
auto operator co_await(S&& sender);
That will make all sender awaitable which means they can be used
in a co_await expression.
The complete prototype implementation is about 100 loc. Not bad.
and now we can write this:
oneway_task task_with_coro(execution::scheduler auto s) {
co_await s.schedule();
printf("Hello"); //runs in thread pool
}
void task_with_spawn(execution::scheduler auto s) {
auto sender = s.schedule();
execution::spawn(std::move(sender), as_receiver([]{
printf("Hello");
}));
}
int main() {
static_thread_pool p(std::thread::hardware_concurrency());
task_with_coro(p.scheduler());
task_with_spawn(p.scheduler());
wait(p.depleted());
}
Pretty magic!1
In fact, this is possible because there is almost a 1/1 mapping between sender/receiver and promise/continuation of coroutines.
The factoring of `submit` into `connect`/`start` gives more flexible ownership semantics, and aligns the design conceptually with coroutines, making coroutines an efficient way of expressing sender/receiver.
— @ericniebler.bsky.social (@ericniebler) October 22, 2019
15 years ago Herb Sutter declared the free lunch over. But with the right set of primitives, we might just be able to have our cake and eat it too.
Customization points
Almost all functions I mentioned are customization points, which means that they can be specialized for specific sender, or receivers, including:
set_value(receiver)set_done(receiver),set_error(receiver)schedule(scheduler)connect(sender, receiver)spawn(sender, receiver)start(operation)
The last CPO I have not yet mentioned is bool is_blocking(sender) that queries whether a sender will call its receiver in the current (inline) execution concept.
Without this, it is very easy to write a program that does not make any forward progress.
The customizations are based on tag_invoke a customization point object mechanism that allows type-erased objects to forward the CPO calls.
While a very neat idea, I cannot help but think this tries to provide a library solution to a language problem.
Bulk execution and properties
P0443R11 also provides for bulk execution and a number of queryable properties to tune the behavior of executors… These are not areas I am very comfortable with for now and this article is getting long, stay tuned.
I also want to explore in the future how we can leverage executors and io_uring, Grand Central Dispatch and Windows Thread Pools.
Because I want to be able to write
co_await socket.write("Hello");
co_await socket.read(buffer);
But here is that word again, executor.
Executors
P0761 explains
An executor is an object associated with a specific execution context. It provides one or more execution functions for creating execution agents from a callable function object. […] Executors themselves are the primary concern of our design.
But because receivers are a more fundamental building block than functions, we can implement an execute function trivially:
void execute(execution_context ctx, invocable auto&& f) {
auto sender = ctx.scheduler().schedule();
spawn(std::move(sender), as_receiver(std::forward<decltype(f)>(f)));
}
So it might be that executors are the least important part of the Executor proposal.
And what that means then is that…
… operation is the basis of operations.
Acknowledgments
Many thanks to Lewis Baker, Eric Niebler, Kirk Shoop and David Hollman for patiently explaining their work.
Saar Raz and Matt Godbolt for providing the tools that allow the examples in this article to compile.
Resources and References
CppCon 2019: Eric Niebler, David Hollman “A Unifying Abstraction for Async in C++”
C++Now 2019: David Hollman “The Ongoing Saga of ISO-C++ Executors”
Papers
P1897 - Towards C++23 executors: An initial set of algorithms - Lee Howes
P1895 - tag_invoke: A general pattern for supporting customizable functions -Lewis Baker, Eric Niebler, Kirk Shoop
P1341 - Unifying Asynchronous APIs in the Standard Library - Lewis Baker
P1436 - Executor properties for affinity-based execution - Gordon Brown, Ruyman Reyes, Michael Wong, H. Carter Edwards, Thomas Rodgers, Mark Hoemmen
P1660 - A Compromise Executor Design Sketch (by Jared Hoberock, Michael Garland, Bryce Adelstein Lelbach, Michał Dominiak, Eric Niebler, Kirk Shoop, Lewis Baker, Lee Howes, David S. Hollman, Gordon Brown
P0443 - A Unified Executors Proposal for C++ - Jared Hoberock, Michael Garland, Chris Kohlhoff, Chris Mysen, Carter Edwards, Gordon Brown, David Hollman, Lee Howes, Kirk Shoop, Eric Niebler
Implementations
Pushmi - Facebook/folly’s implementation of a previous iteration of the Sender/Receiver model.
Corio - The very incomplete and immature project I started recently - the best way to understand something is to implement it. There is barely enough in there to support this blog post
-
Compiler Explorer does not support executing multi-thread code, but they are working on it. Thanks, Matt! ↩︎
Share on